En Buk día a día nos enfocamos en la calidad del código que estamos escribiendo, porque entendemos que nos permitirá resolver problemas a nuestros clientes de forma más rápida, entregándoles nuevas features en menos tiempo.
He aquí el dilema que muchos de ustedes han visto en distintos contextos. Que un proyecto sea rápido, barato y bueno es una utopía. Siempre hay que sacrificar alguno de los anteriores, para cubrir otro.
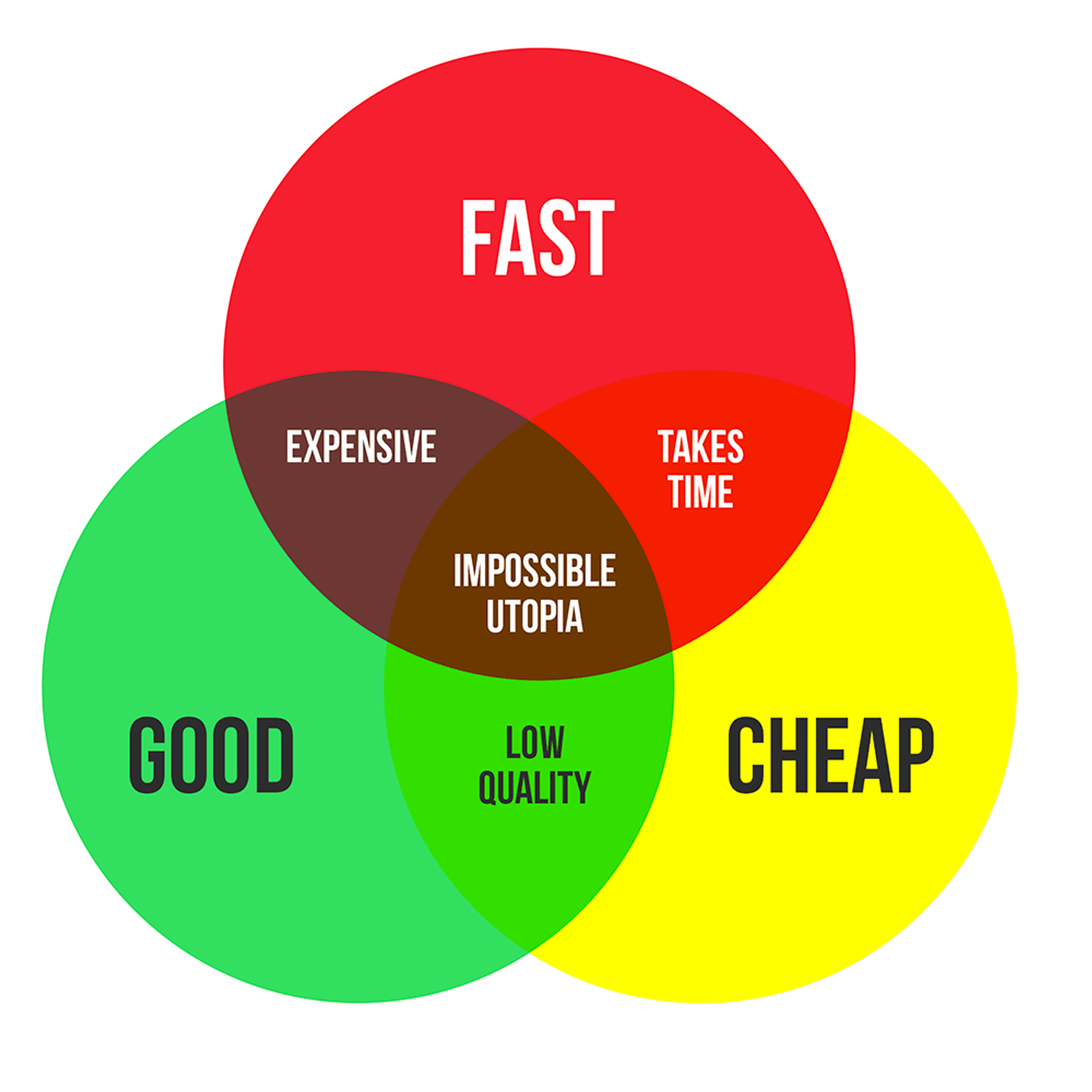
Este fenómeno es bien conocido en la industria del software y usualmente lo que se sacrifica es la calidad, generando el concepto de deuda técnica. Existe mucha bibliografía al respecto por lo que no ahondaré en el tema. Lo importante de la analogía es que como cualquier deuda, si no es pagada genera intereses y cada vez se vuelve más dificil llevarla a 0.
En Buk intuimos que nuestras features van dejando algún grado de deuda técnica, por lo mismo, decidimos (un tanto arbitrariamente) que el 20% del tiempo de nuestros sprints, lo usaríamos para saldar esas deudas.
Happy problem! ¡Tenemos presupuesto para mejorar nuestro codigo! Ahora el problema que nos surgió es, ¿en qué invertimos ese tiempo?.
Decidimos mirar este problema de una manera más integral que solo usar una herramienta de análisis de código estático como lo son los Cops, SonarCloud, etc.
Creemos firmemente que los síntomas de nuestra deuda técnica vuelven en forma de errores (usamos Sentry para monitoreo de errores), de problemas de usabilidad (usamos Freshdesk para la gestión de incidencias), de problemas de velocidad de desarrollo (usamos Jira para la gestión de nuevos features).
Por esto, en una primera etapa tomamos las siguientes fuentes de datos:
- Sentry: Análisis de errores de nuestra aplicación, nuestra heurística es que cada vez que tenemos un error en Sentry tomamos el primer archivo de la traza del error para asignarle un contador (por evento, no por issue)
- Code Maat (Adam Tornhill si estás leyendo, te queremos mucho): Análisis social de la interacción que tiene nuestro repositorio, usando la historia de nuestros commits somos capaces de obtener un promedio móvil de la cantidad de veces que un archivo es cambiado, en teoría un archivo no debería sufrir muchos cambios a lo largo del tiempo, es un warning para nosotros si lo hace. En el repo de Code Maat existen un montón de métricas interesantes a nivel organizacional y de relaciones entre archivos y autores.
- SonarCloud: Análisis de código estático, ofrece un montón de métricas, nos enfocamos en Cognitive Complexity, Duplicated Lines Density y la más obvia de todas Lines of code
- Test Coverage: En nuestro pipeline de CI tenemos un job que nos entrega el test coverage de nuestra app (de momento no tenemos esa parte integrada con SonarCloud y si ya lo tienes, omite este paso).
Otra de las particularidades de Buk es que tenemos un monolito grande, por lo que usamos Codeowners para saber de qué equipo es cada archivo
Tomando estos inputs decidimos crear un Google Colab (que dejaremos al final para que lo puedas probar), para ir revisando los resultados
Sentry
Usamos la API de Sentry para traernos los eventos, obtenemos la traza, buscamos si contiene alguno de nuestros archivos y asumimos que el error es del primer archivo que aparece. Luego contamos y agrupamos por archivo, y finalmente tenemos el total de errores por cada uno de ellos.
SENTRY_API_BASE_URL = 'Replace with your Sentry API base URL'
SENTRY_AUTH_TOKEN = 'Replace with your Sentry authentication token'
PROJECT_ID = 'Replace with your Project Id'
ENVIRONMENT = 'Replace with your enviroment'
ORGANIZATION = 'Replace with your organization'
END_DATE = date.today().strftime("%Y-%m-%d")
START_DATE = (date.today() - relativedelta(years=1)).strftime("%Y-%m-%d")
PAGES = 100 # PAGES * 100 = #records
def get_events_stack_files():
data = []
url = f"{SENTRY_API_BASE_URL}/organizations/{ORGANIZATION}/events/?query=(event.type:error AND has:stack.filename)&field=stack.filename&field=count()&field=transaction&project={PROJECT_ID}&start={START_DATE}&end={END_DATE}&sort=-count()&environment={ENVIRONMENT}"
headers = {
'Authorization': f'Bearer {SENTRY_AUTH_TOKEN}',
'Content-Type': 'application/json',
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
data+=(response.json()['data'])
else:
print(f"Failed to retrieve file statistics. Status code: {response.status_code}")
return None
# We hit the first page to access to pagination next link
for i in range(PAGES-1):
response = requests.get(response.headers['link'].split(';')[3].split(',')[-1].strip()[1:-1], headers=headers)
data+=(response.json()['data'])
return data
stack_files = pd.DataFrame.from_dict(get_events_stack_files())
# After get the 100 pages we normalize the error backtrace to count them
stack_files = stack_files.reset_index()
sentry_stats = pd.DataFrame({'stack.filename': stack_files['stack.filename'].explode(), 'index': stack_files['index'] ,'sentry_errors': stack_files['count()'], 'transaction': stack_files['transaction']})
# We analize code of only one team (we use code owners)
# team_files is a dataframe that only has one column called entity (filename)
sentry_stats = sentry_stats.merge(team_files, left_on='stack.filename', right_on='entity', how='inner')
sentry_stats = (sentry_stats.reset_index()
.drop_duplicates(subset=['stack.filename', 'index'], keep='last'))
sentry_stats = sentry_stats[['entity', 'sentry_errors']]
sentry_stats = sentry_stats.groupby('entity').agg('sum')
Code Maat
Lo primero que debemos hacer es descargar el registro de cambios de Github, esto corriendo lo siguiente dentro de la carpeta de nuestro proyecto:
git log --all --numstat --date=short --pretty=format:'--%h--%ad--%aN' --no-renames --after=2021-06-01 > logfile.log
Con esto descargamos todos los commits que han sido creados desde el 1 de junio del 2022 y se guardan en el archivo logfile.log
A continuación es necesario clonar el repositorio de code-maat, agregar el archivo recien creado (en el root) y proceder a generar el análisis.
Intrucciones para correrlo con Docker:
Paso 1: Construir la imagen de Docker. Dependiendo del computador les podría tocar hacer cambios al dockerfile (para Mac con M1 hay que cambiar la primera línea por FROM clojure:latest). Pueden revisar las issues del repositorio si es que tienen problemas.
docker build -t code-maat-app .
Paso 2: Correr el comando en un nuevo contenedor para la imagen creada y guardar los resultados en un archivo. Una vez creado el contenedor, se pueden correr los comandos con docker exec en vez de docker run para no levantar otro contenedor.
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -c git2 -a age > entity-age.csv
Para obtener el promedio móvil obtenemos 9 ventanas de logs
for i in range(9):
zero_date = (date.today() - relativedelta(months=i)).strftime("%Y-%m-%d")
print(f'docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d {zero_date} -c git2 -a age > entity-age-{i}.csv')
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d 2023-07-18 -c git2 -a age > entity-age-0.csv
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d 2023-06-18 -c git2 -a age > entity-age-1.csv
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d 2023-05-18 -c git2 -a age > entity-age-2.csv
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d 2023-04-18 -c git2 -a age > entity-age-3.csv
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d 2023-03-18 -c git2 -a age > entity-age-4.csv
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d 2023-02-18 -c git2 -a age > entity-age-5.csv
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d 2023-01-18 -c git2 -a age > entity-age-6.csv
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d 2022-12-18 -c git2 -a age > entity-age-7.csv
docker run -v "$PWD":/data -it code-maat-app -l /data/logfile.log -d 2022-11-18 -c git2 -a age > entity-age-8.csv
Teniendo las 9 ventanas tomamos el promedio de ellas, e invertimos la edad para que todas nuestras métricas sean incrementales y signifiquen lo mismo (numero más grande métrica más mala)
ages_stats = team_files
for i in range(9):
age_month = pd.read_csv(f"entity-age-{i}.csv").rename(columns={'age-months': f'age-{i}'})
ages_stats = ages_stats.merge(age_month, on='entity', how='inner')
max_age = ages_stats.drop('entity', axis=1).max(axis=1).max(axis=0)
ages_stats['inverse_avg_age'] = max_age - ages_stats.iloc[:,1:].astype(float).mean(axis=1)
SonarCloud
Obtenemos las métricas via API de Sonar por cada archivo, normalizamos la data para que sea comparable con el resto de las métricas
PROJECT_NAME = 'Replace with your project name'
# Issues endpoint url, more info in https://sonarcloud.io/web_api/
ISSUES_URL = f'https://sonarcloud.io/api/issues/search?projects={PROJECT_NAME}'
TOKEN = 'Replace with your token'
session = requests.Session()
session.auth = TOKEN, ''
def fetch_data(url, session, params):
res = session.get(url, params=params)
json_string = res.content.decode('utf-8')
return json.loads(json_string)
def pages_quantity(url, session, params, ps):
params['p']= 1
data = fetch_data(url, session, params)
try:
total = data['total']
except:
total = data['paging']['total']
return (total // ps) + 1
MEASURES_URL = 'https://sonarcloud.io/api/measures/component_tree'
METRICS = ['complexity','cognitive_complexity','duplicated_lines_density', 'ncloc']
measures = fetch_data(MEASURES_URL, session, {'component': PROJECT_NAME, 'metricKeys': (',').join(METRICS),'qualifiers':'FIL','ps':'1'})
data_list = []
n_pages = pages_quantity(MEASURES_URL, session, {'component': 'bukhr_buk-webapp', 'metricKeys': (',').join(METRICS),'qualifiers':'FIL'}, 500 )
for page in range(1, n_pages + 1):
page_data = fetch_data(MEASURES_URL, session, {'component': 'bukhr_buk-webapp', 'metricKeys': (',').join(METRICS),'qualifiers':'FIL','p': page, 'ps': 500})
data_list.extend(page_data['components'])
sonar_metrics = pd.DataFrame(data_list)
sonar_metrics = sonar_metrics.merge(team_files, left_on='path', right_on='entity', how='inner')
sonar_metrics = sonar_metrics[['entity', 'measures']]
sonar_metrics = sonar_metrics.explode('measures')
metric_keys= ['bestValue', 'metric', 'value']
for key in metric_keys:
sonar_metrics[key] = sonar_metrics['measures'].apply(lambda x: x.get(key))
sonar_metrics.drop(columns=['measures'], inplace=True)
filtered_sonar_metric = []
for metric in METRICS:
filtered = sonar_metrics[sonar_metrics['metric'] == metric]
filtered_sonar_metric.append(filtered.rename(columns={'value': metric}))
grouped_sonar_metric = filtered_sonar_metric[0]
for i in range(1, len(filtered_sonar_metric)):
grouped_sonar_metric = grouped_sonar_metric.merge(filtered_sonar_metric[i], on='entity', how='outer')
metric_stats = grouped_sonar_metric[['entity']+METRICS]
Ponderación
Una vez que tenemos todas las métricas, necesitamos normalizar y ponderar para obtener un número que nos pueda resumir toda la información.
joined_df = sentry_stats.merge(metric_stats,on='entity', how='outer').merge(coverage_stats,on='entity', how='outer').merge(ages_stats,on='entity', how='outer')
s0 = filled_df.iloc[:,1:].astype(float)
normalized_df = pd.concat([filled_df.iloc[:,:1], (s0 - s0.min()) / (s0.max() - s0.min())], axis=1)
normalized_df2 = pd.concat([filled_df.iloc[:,:1], (s0 - s0.mean()) / (s0.std())], axis=1)
weights = {'sentry_errors': 20,
'cognitive_complexity':30,
'duplicated_lines_density':10,
'ncloc':20,
'inverse_coverage':15,
'inverse_avg_age':5}
normalized_df['summary'] = normalized_df.apply(lambda row: sum(row[col] * weight for col, weight in weights.items()), axis=1)
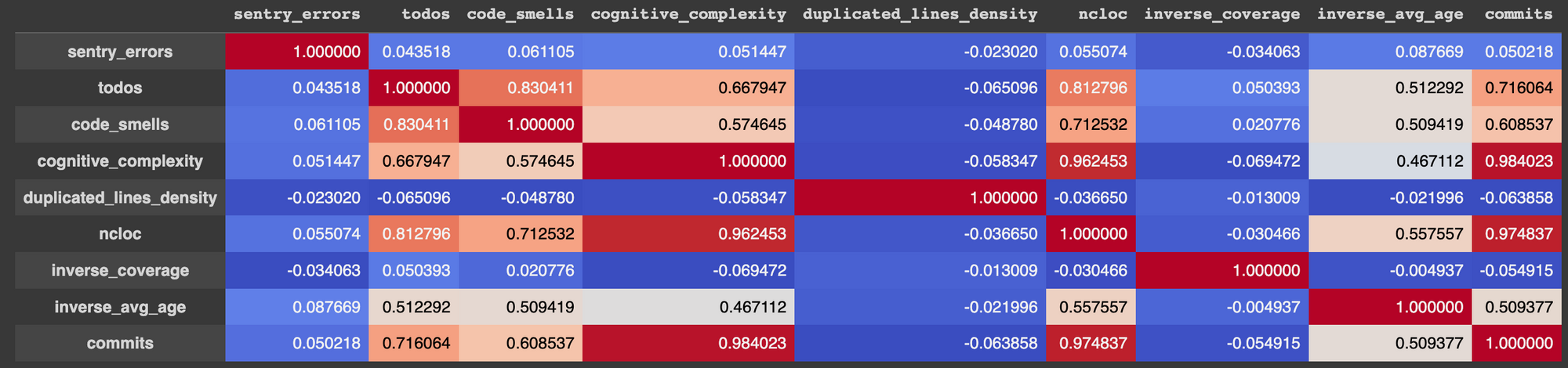
Esto nos permite obtener una matriz de correlación y tener aun más información para poder tomar decisiones.
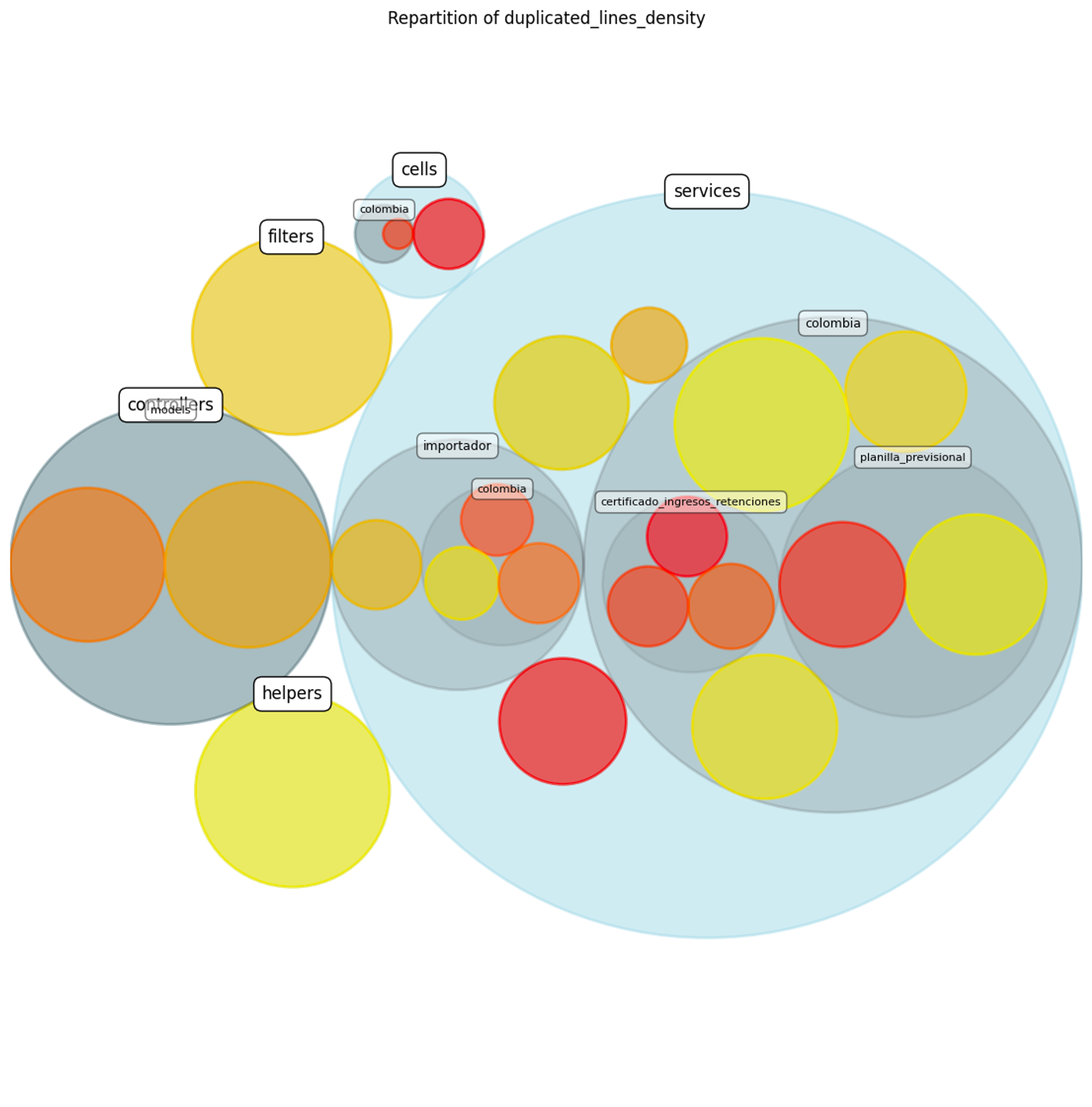
Por último creamos una herramienta (algo básica) basada en el repositorio de Code Maat para poder ver las métricas de forma más visual. En la siguiente imagen se ven nuestras subcarpetas del proyecto, mientras más en rojo más lineas duplicadas y mientras más grande el circulo más líneas de código.
Conclusión
Luego de obtener los datos y resumirlos al máximo, cruzamos esta información con nuestro roadmap para priorizar de mejor manera. Creemos firmemente que resolver aquella deuda técnica del código que modificaremos en el futuro cercano será un empujón para entregar mejores features a nuestros clientes.
La decisión basada en datos junto al conocimiento de cada equipo que comprende a nuestros clientes, hará que podamos enfocar ese 20% de tiempo en resolver deuda técnica relevante para poder tener un mayor y mejor delivery.
Este proyecto nos permitió categorizar, según las necesidades de cada equipo, los archivos y módulos que necesitan un doble click, y así pagar esa deuda que hemos ido acumulando a lo largo de los años, lo hicimos parametrizable dado que no todos los equipos tienen una gran cantidad de sentries u otros equipos donde su coverage está sobre el 80%, éstas métricas que se vuelven irrelevantes para el análisis.