En el dinámico mundo de la orquestación de contenedores con Kubernetes, la gestión eficiente de los recursos es fundamental para garantizar el rendimiento y la estabilidad de las aplicaciones. Uno de los desafíos más comunes y con frecuencia mal interpretados que enfrentan los equipos de desarrollo y operaciones (DevOps) es el CPU throttling (estrangulamiento de CPU o limitación de CPU).
Muchos desarrolladores se encuentran con un enigma frustrante: ¿por qué sus aplicaciones, que vuelan en sus entornos de desarrollo locales, se arrastran en la nube, tardando el doble o incluso el triple de tiempo en completar las mismas tareas? Frecuentemente, la respuesta a esta pregunta reside en un enemigo silencioso y poco comprendido en el mundo de Kubernetes: CPU throttling.
Este fenómeno, invisible a primera vista, puede degradar drásticamente el rendimiento de una aplicación sin generar errores evidentes o fallos en el sistema. Los equipos de desarrollo se esfuerzan por optimizar el código, refactorizar arquitecturas y afinar bases de datos, sin darse cuenta de que el verdadero cuello de botella no está en su software, sino en cómo se gestionan los recursos computacionales a nivel de infraestructura.
¿Qué es el CPU Throttling en Kubernetes?
El CPU throttling es una medida de control de recursos implementada en el kernel de Unix, específicamente diseñada para limitar la cantidad de tiempo de CPU que un contenedor puede consumir. Dentro del ecosistema de Kubernetes, esta técnica se manifiesta como la imposición de límites de CPU a los contenedores que operan dentro de los pods.
Cuando una aplicación, encapsulada en un contenedor, intenta superar la cuota de CPU que le ha sido asignada, el programador del kernel, en particular el Completely Fair Scheduler (CFS), interviene para “estrangularla”. Esta acción se traduce en una ralentización de la ejecución de la aplicación, asegurando que no exceda el límite de CPU establecido. El objetivo principal de este mecanismo es prevenir que un único contenedor monopolice los recursos de la CPU, garantizando así una distribución justa y eficiente entre todas las cargas de trabajo en el nodo. Sin el throttling, un contenedor con una demanda de CPU muy alta podría impactar negativamente el rendimiento de otras aplicaciones críticas que se ejecutan en el mismo servidor.
La especificación del límite de CPU se realiza en la configuración del contenedor dentro del Pod a través del parámetro resources.limits.cpu. Este valor se expresa comúnmente en milicores, una unidad que permite una granularidad fina en la asignación de recursos. Por ejemplo, la expresión 500m indica que el contenedor tiene derecho a utilizar la mitad de una CPU (o un núcleo), mientras que 1000m representa el acceso a una CPU completa. Es importante destacar que, si bien se pueden asignar valores superiores a 1000m (por ejemplo, 2000m para dos CPUs), la disponibilidad real dependerá de los recursos físicos del nodo donde se ejecute el pod.
Más allá de los límites, también es posible establecer resources.requests.cpu, que indica la cantidad mínima de CPU que el programador de Kubernetes intentará garantizar para el contenedor. Si bien requests influye en la programación inicial de los pods en los nodos (asegurando que el nodo tenga recursos disponibles para la solicitud), limits es el valor que activa el throttling si el consumo excede el tope. La interacción entre requests y limits es crucial para optimizar la utilización de los recursos y mantener la estabilidad del sistema.
El CPU throttling, aunque fundamental para la estabilidad y el rendimiento de un cluster de Kubernetes, puede tener efectos secundarios si no se configura adecuadamente. Un límite de CPU demasiado bajo puede provocar que las aplicaciones se ejecuten más lentamente de lo esperado, resultando en latencia o degradación del servicio. Por otro lado, no establecer límites adecuados puede llevar a escenarios donde un solo pod consume todos los recursos, afectando a otros pods en el mismo nodo. Por lo tanto, la monitorización continua del uso de CPU y la optimización de los límites son prácticas esenciales para mantener un entorno de Kubernetes saludable y eficiente. Herramientas de monitorización permiten observar los patrones de consumo de CPU e identificar cuándo se está produciendo throttling, lo que ayuda a los administradores a ajustar los límites para lograr un equilibrio óptimo entre rendimiento y estabilidad.
¿Cómo ocurre el CPU Throttling?
Contrario a lo que se podría pensar, una CPU no se puede ser dividida en partes menores. Lo que sí es divisible es el tiempo de uso de la CPU. Para gestionar y limitar este periodo de utilización, interviene el Completely Fair Scheduler (CFS). Kubernetes traduce los cpu.limits definidos en el manifiesto de un pod a dos parámetros del CFS cgroup:
-
cpu.cfs_period_us: Generalmente establecido en100,000microsegundos (100ms), este es el período de tiempo sobre el cual se mide el uso de la CPU. -
cpu.cfs_quota_us: Esta es la cantidad total de tiempo de CPU (en microsegundos) que un contenedor puede utilizar dentro de uncfs_period_us.
Por ejemplo, si se establece un cpu.limit de 500m (medio core), Kubernetes configurará la cpu.cfs_quota_us en 50,000 microsegundos. Esto significa que el contenedor podrá usar 50ms de tiempo de CPU cada 100ms. Si intenta usar más, será puesto en espera hasta el próximo período, resultando en latencia y una degradación del rendimiento perceptible.
Un ejemplo práctico
Imaginemos una aplicación web con un endpoint que responde en un promedio de 100ms. Consideremos también que nuestro cpu.cfs_period_us está configurado por defecto a 100,000 microsegundos (100ms). Adicionalmente, se han establecido los siguientes límites de CPU para los contenedores:
- App Web:
300m(equivalente a30msdel período) - App 2:
700m(equivalente a70msdel período)
A continuación, visualicemos el impacto del CPU Throttling en la imagen siguiente:
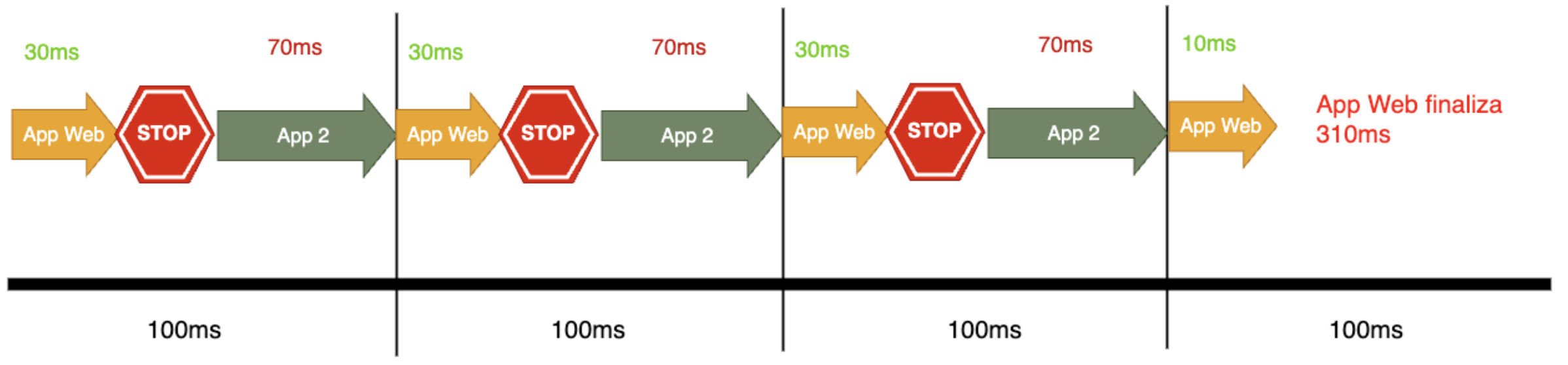
Como se observa, la aplicación web demoró 310ms en procesarse, a diferencia de los 100ms habituales. Esto se debe a la limitación de 300m de CPU del contenedor, que solo permitió procesar 30ms de los 100ms del período de procesamiento de la CPU.
Para que la aplicación web se ejecute en 100ms, sería necesario asignar el 100% de una CPU (es decir, 1000m de cpu.limit). Esto permitiría procesar la totalidad de los 100ms del período de tiempo de la CPU, eliminando la latencia. La App 2 utilizaría otra CPU del nodo, compartida con otros contenedores.
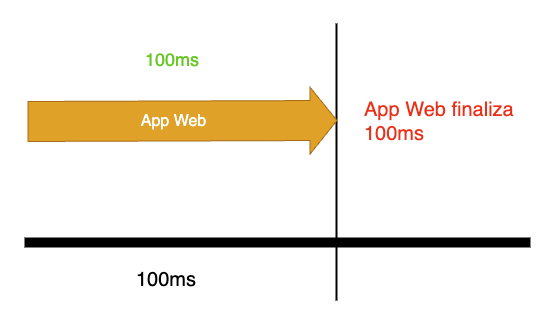
A primera vista, podría parecer ideal configurar la CPU a 1000m para utilizar el 100% de su capacidad. Sin embargo, es crucial evitar una cantidad excesiva de CPU inactiva en ciertos periodos. Es fundamental comprender el comportamiento de los procesos: un proceso utiliza la CPU hasta que requiere una operación de I/O (Input/Output, Entrada o Salida), como consultas a la base de datos, HTTP o disco. Si el proceso es multihilo, como un servidor web, ejecutará múltiples subprocesos simultáneamente, donde cada hilo alternará el uso de la CPU a medida que se ejecuten las operaciones de I/O. En ese caso del servidor web, hace sentido tener 100% de la CPU, pero si tenemos algún proceso que no es multihilo, quizás no.
Impacto en diferentes tipos de cargas de trabajo
-
Aplicaciones Sensibles a la Latencia (por ejemplo, APIs web): El CPU throttling puede tener un impacto devastador en los tiempos de respuesta. Es importante tener muy bien configurado el límite de CPU.
-
Trabajos por Lotes (Batch Jobs): Para cargas de trabajo que no son sensibles al tiempo, el CPU throttling puede ser aceptable e incluso deseable para asegurar que no acaparen recursos del cluster.
Las causas más comunes del CPU Throttling
-
Límites de CPU mal configurados: Establecer límites demasiado bajos para las necesidades reales de la aplicación es la causa más frecuente.
-
Cargas de trabajo con ráfagas (Bursty Workloads): Aplicaciones que tienen picos de uso de CPU pueden alcanzar rápidamente sus límites y ser estranguladas, incluso si el uso promedio de CPU es bajo.
-
Procesos de arranque intensivos: Algunas aplicaciones consumen una cantidad significativa de CPU al iniciarse, lo que puede llevar a un throttling inmediato si los límites no lo contemplan.
Monitoreo continuo y alertas
Implemente alertas en su sistema de monitoreo para notificarle cuando las tasas de CPU throttling excedan un umbral predefinido. Esto le permitirá abordar proactivamente los problemas de rendimiento antes de que afecten a sus usuarios.
Consultas PromQL de ejemplo
Para visualizar la tasa de estrangulamiento por pod en los últimos 5 minutos, puede usar la siguiente consulta en PromQL:
sum(rate(container_cpu_cfs_throttled_seconds_total{namespace="$namespace", container!=""}[5m])) by (pod) > 0
Podemos usar esta métrica para determinar el porcentaje de periodos en los que hubo CPU Throttling en los últimos 5 minutos:
sum(increase(container_cpu_cfs_throttled_periods_total{namespace="$namespace", container!=""}[5m])) by (pod) / sum(increase(container_cpu_cfs_periods_total{namespace="$namespace", container!=""}[5m])) by (pod) > 0
Conclusión
El CPU throttling en Kubernetes se revela como una espada de doble filo. Por un lado, es un mecanismo de salvaguarda indispensable que protege la estabilidad del cluster y garantiza una distribución justa de los recursos. Por otro lado, cuando no se gestiona adecuadamente, se convierte en el “enemigo silencioso” que da título a este artículo: una causa sutil pero potente de latencia y degradación del rendimiento que puede frustrar a usuarios y desarrolladores por igual.
La clave para dominar este desafío no reside en eliminar los límites de CPU, sino en gestionarlos con inteligencia y precisión. Como hemos visto, la solución pasa por una estrategia integral que combina:
-
Entendimiento Profundo: Comprender que los límites de CPU son en realidad límites de tiempo de uso, regidos por el Completely Fair Scheduler (CFS) del kernel de Linux.
-
Configuración Consciente: Realizar un perfilado de las aplicaciones para establecer
requestsylimitsque reflejen sus necesidades reales, dando espacio para las ráfagas (bursts) sin dejar el cluster expuesto. -
Monitoreo Proactivo: Utilizar herramientas como Prometheus para vigilar activamente las métricas de throttling y así detectar problemas antes de seguir impactando a los usuarios.
En última instancia, transformar el CPU throttling de un adversario oculto a un aliado predecible es una señal de madurez en la operación de Kubernetes. Es el paso definitivo para asegurar que nuestras aplicaciones no solo funcionen, sino que prosperen, entregando el rendimiento, la escalabilidad y la fiabilidad que el ecosistema de contenedores promete. La gestión eficaz de los recursos no es solo una tarea técnica; es la base sobre la que se construyen servicios digitales de excelencia.