Construir productos con IA implica un cambio profundo en cómo pensamos el software. Venimos de un mundo principalmente determinista: frente al mismo input, esperábamos el mismo output. Con modelos de lenguaje grandes (Large Language Models, LLM), entramos a un terreno no determinista, donde un mismo input puede derivar en respuestas distintas.
Ese cambio trae una consecuencia práctica: si queremos operar funcionalidades (features) con IA en producción, necesitamos pasar de “se siente bien / se siente mal” a entender con datos qué está pasando, por qué falla y cómo mejorarlo. Ahí es donde la observabilidad deja de ser opcional.
Antes de implementar la solución, el uso de IA en la plataforma carecía de un sistema centralizado de observabilidad. En la práctica, eso nos complicaba:
- Entender cómo los usuarios interactúan con los modelos.
- Medir calidad y efectividad de prompts y respuestas.
- Detectar errores o comportamientos inesperados temprano.
- Tener métricas comparables para evaluar evolución en el tiempo.
- Determinar el origen de errores y su causa.
Cuando un usuario recibía una respuesta poco útil, no teníamos una forma confiable de responder preguntas básicas:
- ¿Qué prompt se usó?
- ¿Cuánta latencia hubo?
- ¿Qué parte del flujo falló?
- ¿Se está repitiendo este patrón?
- ¿Cuánto cuesta?
Sin una visión unificada del rendimiento (performance), costo y calidad, terminábamos dependiendo de percepciones subjetivas en lugar de datos objetivos para iterar.
Qué significa “observabilidad” en aplicaciones con LLM
En sistemas con LLM, observabilidad no es solo tener logs. Es tracing end-to-end (trazabilidad de extremo a extremo) de cada interacción para entender:
- Latencia por paso: dónde se está yendo el tiempo (retrieval (recuperación), generación, tool calls (llamadas a herramientas), post-processing (post-procesamiento)), para atacar el cuello de botella y no solo mirar la “latencia total”.
- Costo por interacción: cuántos tokens consumimos en input y output, cuánto cuesta cada conversación y cómo evoluciona con cambios en prompts, modelos o herramientas.
- Errores: qué falló, en qué etapa, con qué frecuencia y con qué patrón (timeouts (tiempos de espera), fallas de tools (herramientas), errores de parsing (parseo)), para priorizar fixes por impacto real.
- Uso real: cómo usan la funcionalidad, qué inputs se repiten, qué flujos se activan y qué combinaciones llevan a mejores (o peores) resultados.
- Calidad: señales directas e indirectas de utilidad (feedback humano, scores, evaluaciones automáticas), para mejorar respuestas sin depender de casos anecdóticos.
Nuestra solución
Liderando la iniciativa, evalué distintas herramientas del mercado para observabilidad y gestión de aplicaciones con LLM, considerando funcionalidades, SDKs, costos, limitaciones, riesgos técnicos y trade-offs (compromisos).
Junto a los stakeholders (partes interesadas), decidimos implementar Langfuse porque cubre exactamente lo que necesitábamos: trazabilidad, monitoreo, detección y diagnóstico de errores, evaluaciones, métricas, dashboards y prompt management (gestión de prompts). Además, al ser open-source, permite self-hosting (autoalojamiento) en infraestructura de Buk (AWS), lo que nos entrega control, privacidad y escalabilidad. Por último, Langfuse tiene una comunidad activa y, en la práctica, se ha convertido en un estándar de facto para observabilidad en aplicaciones con LLM.
Junto a nuestro practicante Bastián Salomon Avalos, nos pusimos a configurar Langfuse en Buk. Para lograrlo, fue necesario:
- Armar una solución técnica con un plan de trabajo sólido y documentado.
- Crear stacks de Terraform para gestionar la infraestructura necesaria.
- Configurar el chart de Langfuse en Kubernetes.
- Configurar Langfuse con sus parámetros iniciales.
- Definir políticas de acceso a la herramienta.
- Configurar el SSO de Buk y el control de acceso para evitar un uso indiscriminado.
- Crear una librería de Langfuse para la aplicación, reutilizable por todos los servicios y lo menos invasiva posible.
- Configurar el monitoreo de la infraestructura de Langfuse con dashboards, alertas específicas y runbooks para resolución de incidentes.
- Documentar el proceso en los repositorios de Buk y en nuestras plataformas de documentación.
La herramienta nos permitió monitorear y observar la IA en Buk de extremo a extremo:
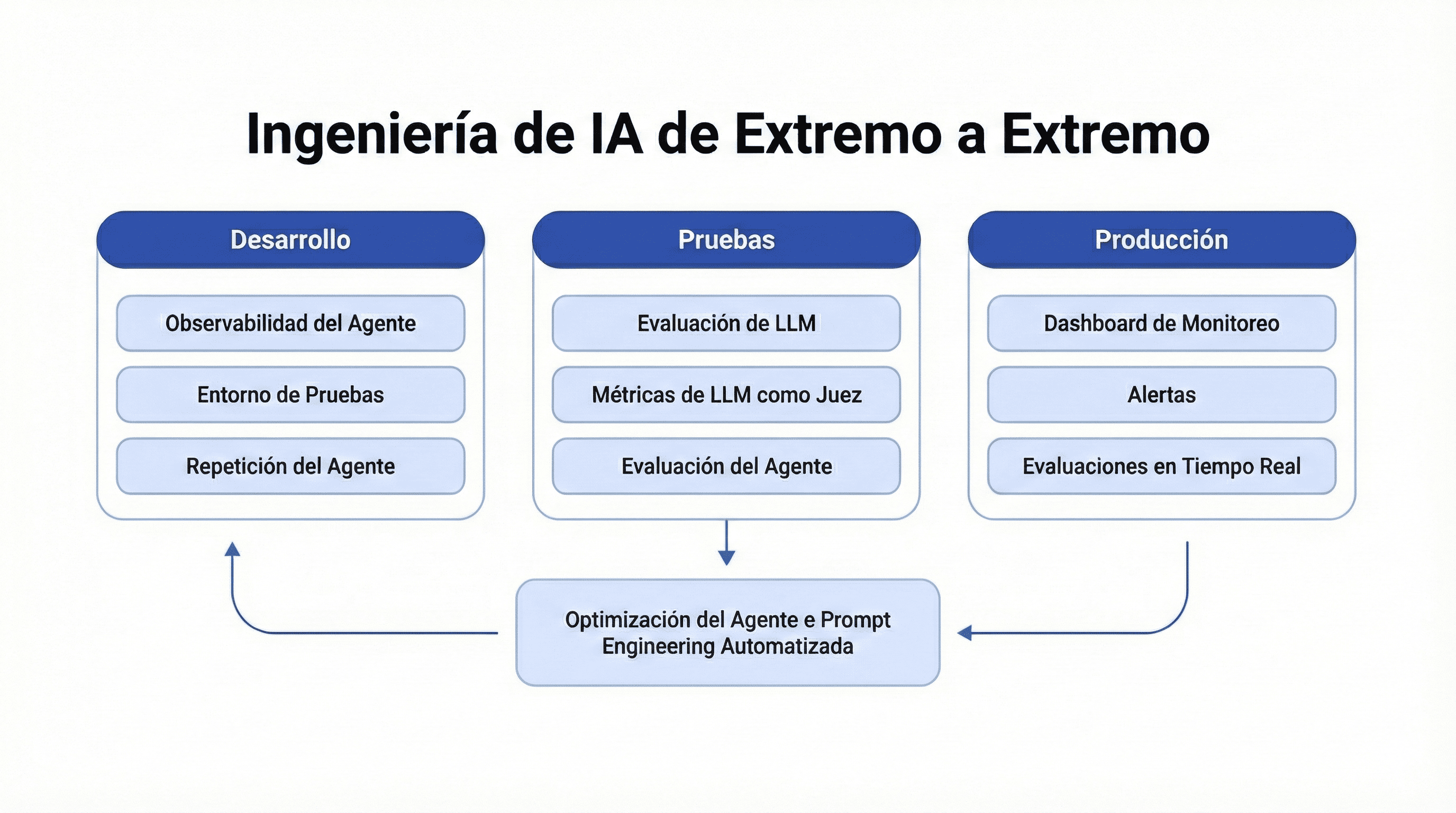
Por qué Langfuse
Estas fueron las ventajas que más pesaron en la decisión:
- Trazabilidad y monitoreo integral para debugging y optimización.
- Identificación temprana de errores en prompts, herramientas y cadenas.
- Métricas y dashboards para costo, latencia y uso.
- Prompt management para iterar sin amarrar todo a ciclos de deploy.
- Evaluaciones automáticas y humanas (human-in-the-loop).
- Open-source + self-hosting (privacidad y control).
Langfuse
Cómo modela Langfuse la observabilidad (conceptos clave)
Langfuse se apoya en un modelo de datos inspirado en OpenTelemetry, con una estructura que calza bien con cómo se componen las apps con LLM.
Traces
Un trace normalmente representa una solicitud u operación completa: incluye input/output generales y metadata relevante (por ejemplo: usuario, sesión, tags).
Observations y nesting
Un trace puede contener múltiples observations: los pasos individuales dentro de la ejecución (y pueden anidarse). Esto permite ver el “árbol” de lo que ocurrió, no solo el resultado final.
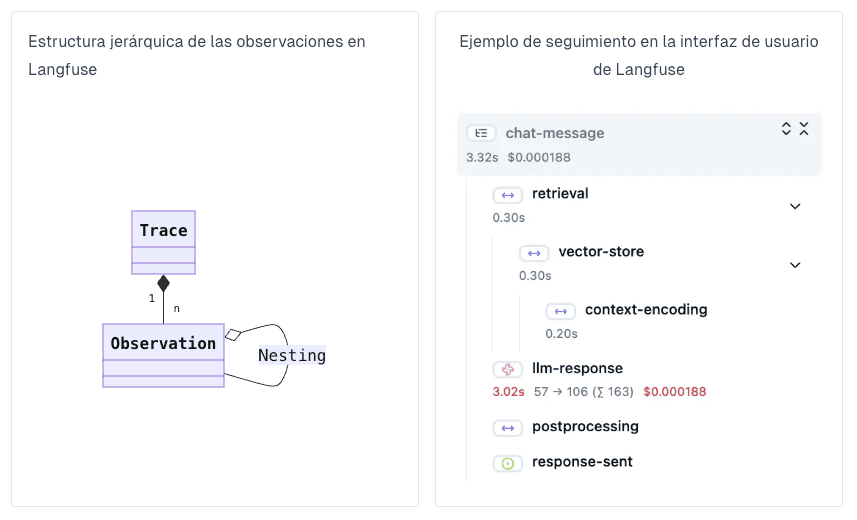
Types
Langfuse soporta distintos tipos de observaciones, pensadas para aplicaciones LLM. Por ejemplo:
event: eventos discretos.span: duraciones de unidades de trabajo.generation: generaciones del modelo (prompts, tokens, costos).agent: decisiones de flujo (por ejemplo, orquestar tools).tool: llamada a herramientas externas.chain: encadenamiento de pasos.retriever: recuperación de información (ej. vector DB / DB).embedding: generación de embeddings.guardrail: validaciones y evaluaciones de seguridad (detección de contenido riesgoso o intentos de jailbreak).
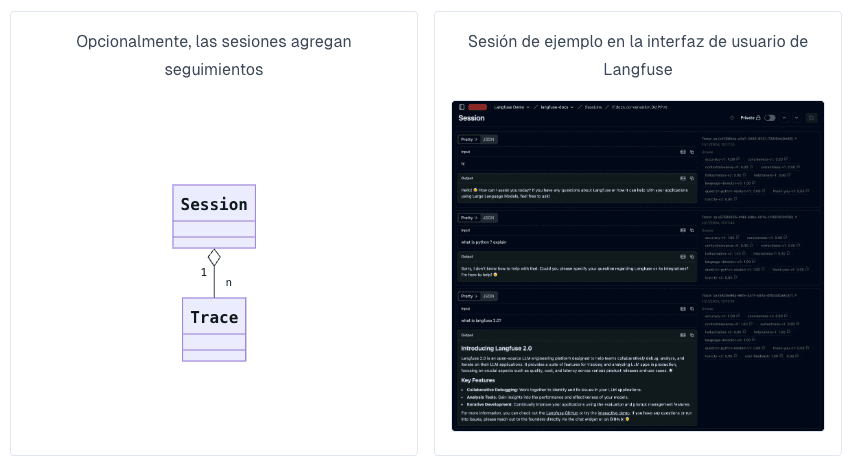
Sessions
Las sessions agrupan traces que forman parte de una misma interacción del usuario (por ejemplo, un hilo de chat). Esto es clave cuando quieres entender “la experiencia completa” y no una sola llamada aislada.
Scores
Los scores son objetos flexibles para evaluación. Pueden ser numéricos, categóricos o booleanos, y se asocian a:
- Trace (una interacción)
- Session (experiencia conversacional completa)
- Dataset run (evaluación sobre un set de casos)
Esto nos permite conectar observabilidad con calidad de forma explícita.
Otras funcionalidades
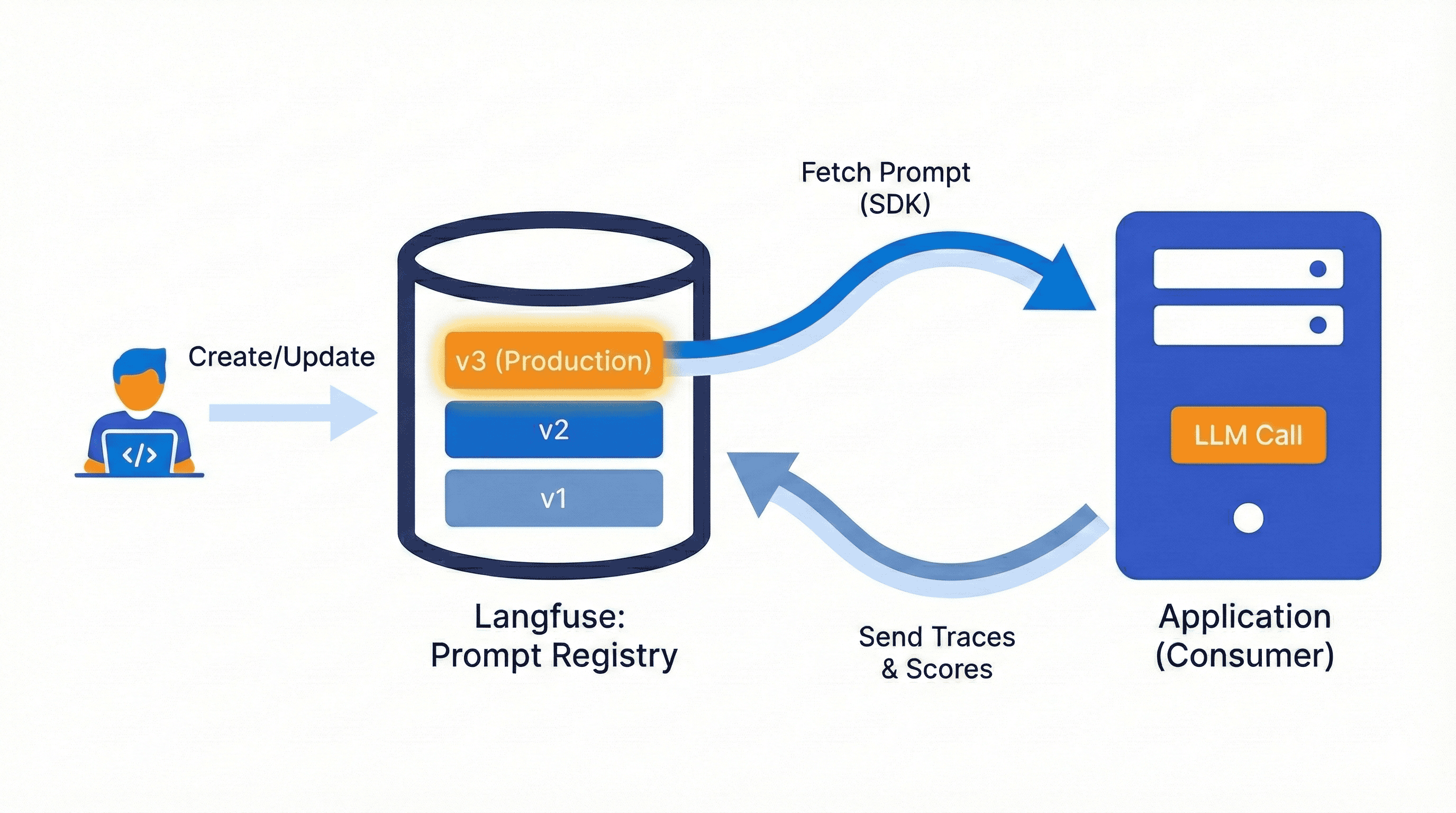
Prompt Management
Prompt management (gestión de prompts) es un enfoque sistemático para almacenar, versionar y recuperar prompts desde un lugar central, en vez de hardcodearlos en el código.
En el día a día, esto reduce fricción:
- Evita que un cambio de texto se transforme en un ciclo completo de ingeniería.
- Permite iterar más rápido y con control de versiones.
- Separa responsabilidades: personas no técnicas pueden iterar prompts, mientras ingeniería se enfoca en la implementación.
Evaluations: detectar regresiones antes de que lleguen a producción
Las evaluations (evaluaciones) nos permiten comprobar de forma repetible el comportamiento de una aplicación LLM.
Una funcionalidad potente es LLM as a Judge (LLM como juez): usar un LLM con un prompt especializado para clasificar o puntuar resultados. Combinado con feedback humano (human-in-the-loop), esto habilita un loop de mejora continuo.
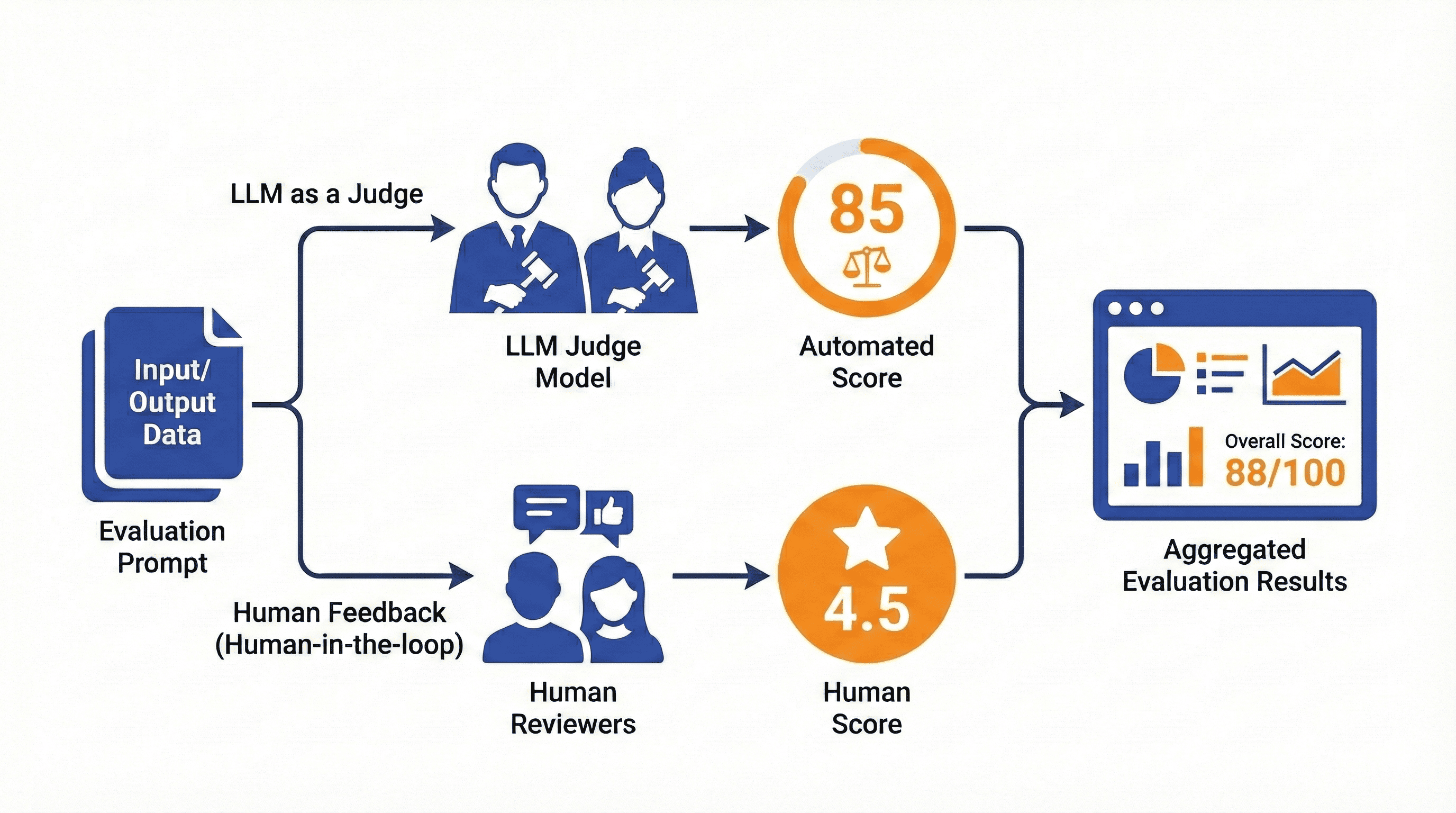
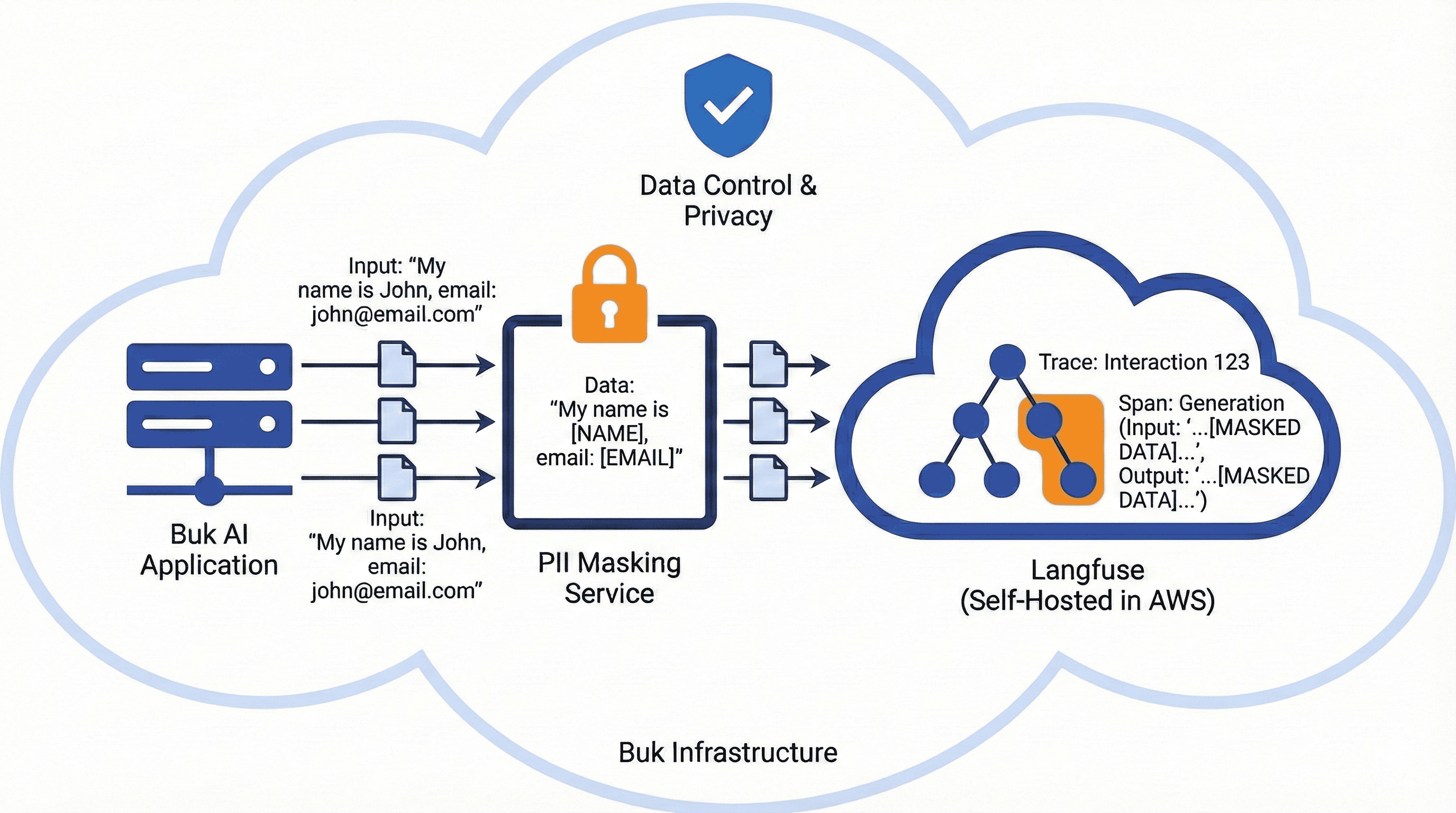
Seguridad y privacidad
La protección de datos es prioridad. Por eso, implementamos un servicio de enmascaramiento de datos que previene exponer PII (Información Personal Identificable) al reemplazar valores sensibles por etiquetas genéricas como [EMAIL], [PHONE], [ID] o [TOKEN] tanto en los inputs (entradas) como en los outputs (salidas) de las trazas y observaciones.
Además, al ser self-hosted (autoalojado) en nuestra infraestructura (AWS), mantenemos control sobre los datos y sobre el alcance: qué clientes y qué servicios específicos se monitorean.
Adicionalmente, en Buk no utilizamos las conversaciones con el LLM para entrenar modelos (ni internos ni de terceros). Las trazas y observaciones las usamos únicamente con fines operativos: mejorar nuestros servicios, depurar incidentes y iterar sobre nuestros prompts.
Para lograrlo sin comprometer la confidencialidad, trabajamos bajo el principio de mínima exposición: no incorporamos datos identificables del cliente en los registros y, cuando necesitamos ejemplos para análisis, documentación o pruebas, usamos la misma estructura de los eventos pero con datos sintéticos y/o enmascarados.
Conclusión
Operar features con IA en producción es distinto a operar software “clásico”. Cuando el sistema es no determinista, el desafío ya no es solo “que funcione”, sino poder explicar qué pasó, medir su desempeño y mejorar sin adivinar. Sin observabilidad, la IA se vuelve una caja negra: cuesta depurar, cuesta controlar costos, y cuesta saber si realmente estamos entregando valor al cliente.
Implementar Langfuse nos permitió pasar de percepciones a datos: entender el comportamiento real de nuestros servicios de IA, observar dónde se concentraban los errores, qué partes del flujo agregaban latencia, y cómo se distribuían los costos (tokens y USD) por interacción. Esa visibilidad habilita un ciclo sano de iteración: mejorar prompts, ajustar el uso de tools, comparar resultados en el tiempo y tomar decisiones con métricas consistentes.
Además, lo hicimos con foco en seguridad. La observabilidad no puede ser a costa de la privacidad: por eso incorporamos enmascaramiento de PII y mantenemos control sobre el alcance del monitoreo. La meta es simple: tener un sistema que sea operable, medible y seguro, incluso cuando el output no sea siempre el mismo.
Y esto no fue solo “instalar una herramienta”: implicó convertir la observabilidad en una capacidad transversal. Al levantar la infraestructura con Terraform, desplegar en Kubernetes, integrar SSO y dejar una librería reutilizable para instrumentar servicios, logramos que la adopción sea consistente y escalable. En otras palabras, pasamos de tener diagnósticos puntuales a contar con una base técnica y operativa que permite sumar nuevos casos de uso y nuevos equipos sin reinventar el camino cada vez.
En futuras publicaciones profundizaremos en dos piezas clave de esta estrategia: Prompt Management y Evaluations. Ahí está gran parte del “cómo” seguimos mejorando: versionar prompts con control y evaluar cambios para detectar regresiones antes de que impacten la experiencia de nuestros clientes.