Cuando trabajas con software “clásico”, la mayor parte de tus controles de calidad viven en tests deterministas y en un pipeline de CI/CD: compilas, ejecutas tests, haces deploy (despliegue).
En cambio, cuando tu producto depende de Large Language Models (LLM), tu sistema se vuelve parcialmente no determinista: para un mismo input (entrada), puedes observar distintos outputs (salidas). Esto cambia la forma de iterar.
En Buk, este problema aparece especialmente fuerte cuando iteramos sobre prompts: un cambio pequeño en texto puede mejorar un caso, pero degradar otro; puede cambiar el tono; o alterar el uso de herramientas (tool calls). Si quieres iterar rápido, necesitas una forma repetible de medir “si quedó mejor” sin depender de percepciones.
En ese contexto, un prompt es código, pero no se comporta como código:
- Cambia el comportamiento del modelo sin que el cambio sea fácil de probar por igualdad exacta.
- Pequeños ajustes pueden afectar tono, precisión y formato.
- El modelo puede responder distinto entre ejecuciones.
Entonces, si haces un despliegue de prompts con un ciclo clásico de CI/CD (como si fueran cambios deterministas), terminas con dos riesgos:
- Prompts “aprobados” por intuición, que en realidad degradan casos reales.
- Iteraciones lentas, porque cada ajuste requiere un ciclo completo de ingeniería.
Para abordar este problema, lideré una iniciativa en Buk, como Staff Software Engineer del equipo de Core AI, para implementar el marco CC/CD (Continuous Calibration / Continuous Development), apoyándonos en evaluaciones offline y online con Langfuse (herramienta que comenté en mi post anterior). Este enfoque está inspirado en el concepto de CC/CD popularizado en el artículo Why your AI product needs a different approach than CI/CD de Aishwarya Naresh Reganti y Kiriti Badam.
CC/CD (Continuous Calibration / Continuous Development)
En lugar de pensar en build -> test -> deploy para prompts, adoptamos el paradigma CC/CD, que nos permite iterar sobre prompts de forma más rápida y segura. La idea central es que el deploy no es una meta: es una transición dentro de un ciclo (loop) guiado por CD y CC.
Continuous Development (Desarrollo Continuo)
- Definimos nuestros prompts (en versiones) con base en el caso de uso o flujo de trabajo.
- Creamos un dataset con casos representativos para evaluar el comportamiento esperado de cada prompt.
- Diseñamos evaluaciones (métricas) específicas para el caso de uso y definimos los jueces que calificarán las respuestas del modelo.
Continuous Calibration (Calibración Continua)
- Cada vez que se crea o modifica un prompt, lo “calibramos” contra un dataset de prueba con ground truth (verdad fundamental).
- Medimos precisión, tono y uso de herramientas con evaluaciones automáticas.
- Solo consideramos “válido” el cambio si cumple umbrales de calidad (por ejemplo
>= 0.6en una escala0..1). - Ya en producción, corremos evaluaciones sobre datos de uso real, analizamos patrones de error y aplicamos correcciones de forma iterativa.
- Muchas mejoras ocurren sin “reinventar todo”: ajustamos prompts, datos, recuperación o componentes, y volvemos a evaluar.
Evaluaciones offline y online en Langfuse
Evaluación offline
Las evaluaciones offline en Langfuse se utilizan para validar y calibrar prompts antes de llevarlos a producción o antes de aprobar cambios relevantes sobre prompts existentes.
El proceso funciona así:
- Definición de un dataset de prueba: Para cada prompt se construye un dataset controlado que contiene:
- Inputs representativos de usuarios reales.
- Un ground truth (o “respuesta esperada”), que define qué se considera una respuesta correcta para cada input.
-
Ejecución del prompt sobre el dataset: Cada vez que se crea o modifica un prompt, este se ejecuta contra el dataset completo. Esto permite observar el comportamiento del modelo de forma sistemática y comparable entre versiones.
-
Evaluación con métricas automáticas (LLM-as-a-Judge): Dado que los LLMs son no deterministas, no se espera una coincidencia exacta con el ground truth (verdad fundamental). En su lugar, se evalúa la calidad de la respuesta mediante criterios deseados (ejemplos: precisión, tono, uso de herramientas).
-
Validación por umbrales de calidad: Un prompt se considera válido solo si sus resultados se mantienen dentro de umbrales aceptables de forma consistente en el dataset. Esto asegura que el cambio no degrade la calidad, mantenga coherencia de tono y respete los comportamientos esperados del sistema.
- Aprobación del prompt: Solo los prompts que superan esta calibración offline deben avanzar a producción o ser usados como base para monitoreo online.
Datasets
En Langfuse los datasets son conjuntos estructurados de datos diseñados para probar y evaluar aplicaciones basadas en LLM. Funcionan como la base de los experimentos, donde una versión específica de un prompt se ejecuta sobre el dataset para medir su desempeño de forma controlada y comparable. Su uso es clave para realizar evaluaciones offline, aplicar evaluadores de tipo LLM-as-a-Judge y medir la calidad general del sistema en escenarios específicos. Esto permite calibrar y validar cambios antes de su despliegue.
Para cada prompt construimos un dataset controlado, compuesto por casos representativos, que contiene:
- Inputs (entradas) representativos de casos reales.
- Un ground truth (verdad fundamental) por caso.
- Metadata útil para segmentar (por ejemplo: idioma, tipo de solicitud, variante del flujo).
No esperamos coincidencia exacta con el ground truth. El objetivo es evaluar si la respuesta cumple criterios.
Verdad fundamental
En Langfuse, la verdad fundamental (ground truth) de un dataset corresponde a las salidas esperadas que usas como base para evaluar el rendimiento de tu aplicación basada en LLM.
Cada elemento del dataset contiene un input (el escenario o pregunta a probar) y, opcionalmente, un expected_output (la salida esperada). Ese expected_output es tu ground truth: la respuesta ideal contra la cual comparas las respuestas generadas por tu aplicación.
La verdad fundamental sirve para:
- Evaluación sistemática: Comparar las respuestas de tu aplicación con respuestas esperadas conocidas.
- Medición de calidad: Implementar evaluaciones que contrasten la respuesta generada con la verdad fundamental.
- Iteración continua: Identificar casos límite en producción y agregarlos al dataset para mejorar progresivamente el conjunto de evaluación.
LLM-as-a-Judge (LLM como juez)
Es una técnica para evaluar salidas generadas por un modelo usando otro LLM como “juez”. En vez de exigir que la respuesta calce palabra por palabra con la verdad fundamental, definimos criterios y una rúbrica, y le pedimos al juez que puntúe qué tan bien se cumplen.
La forma práctica de pensarlo es:
- Tenemos un caso (input del usuario + contexto).
- Tenemos una respuesta del sistema (lo que generó el modelo con el prompt actual).
- Tenemos una rúbrica (qué significa “bueno” para este caso de uso).
- El juez entrega un score por criterio (idealmente en una escala continua como
0..1) y, si es útil, una razón breve.
En Buk, implementamos LLM-as-a-Judge con Langfuse con prompts personalizados y específicos para cada caso de uso.
Arquitectura y flujo de trabajo en Buk
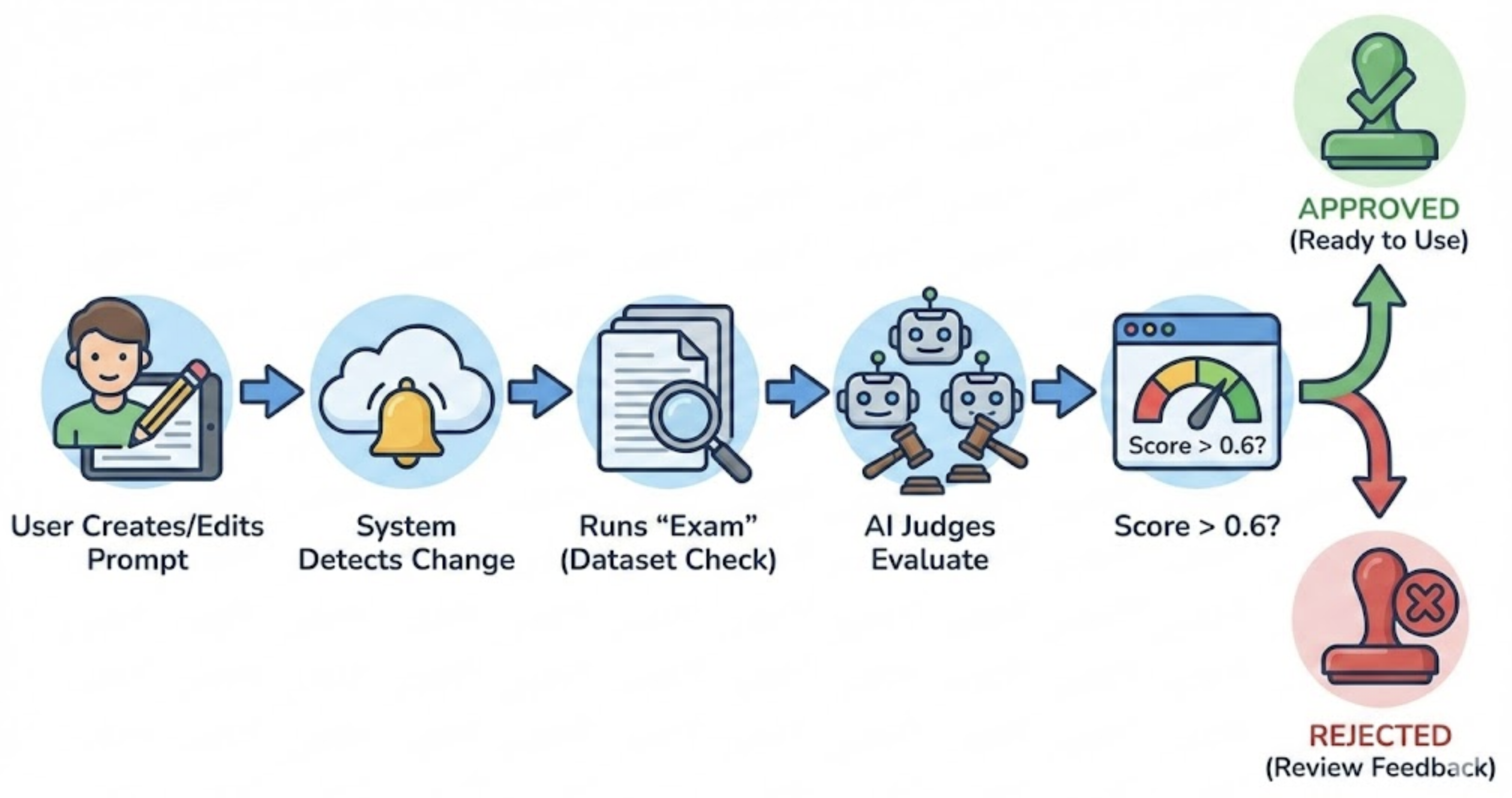
A alto nivel, el flujo automatizado de evaluación de prompts se ve así:
- Un prompt se crea o modifica.
- Se dispara una calibración offline.
- Se calculan scores con LLM-as-a-Judge.
- Se validan umbrales.
- Si pasa, el prompt queda “aprobado” y habilitado para despliegue controlado y monitoreo.
En nuestra implementación, conectamos dos piezas principales:
- Jenkins: orquesta la ejecución del pipeline Offline.
- Langfuse: centraliza gestión de prompts, trazabilidad y evaluación (incluyendo dataset runs y scores).
Evaluación online
Las evaluaciones online corren sobre tráfico real de producción. En vez de partir de un dataset controlado, tomas las trazas que se generan en vivo y les asignas puntajes a cada interacción para medir calidad de forma continua.
Estos puntajes pueden venir de distintos mecanismos, como LLM-as-a-Judge o anotaciones humanas, y sirven para monitorear el comportamiento del sistema en condiciones reales: detectar degradaciones, errores recurrentes y desviaciones de tono antes de que escalen.
La diferencia clave con las evaluaciones offline es el objetivo: offline te ayuda a validar cambios antes de desplegar; online te ayuda a observar y calibrar el sistema mientras está siendo usado.
Buenas prácticas y trade-offs que aprendimos
- Tu dataset es un producto: si no lo actualizas con casos reales, tu calibración se vuelve optimista.
- LLM-as-a-Judge no es “verdad absoluta”: por eso importa versionar el prompt juez y monitorear su estabilidad.
- Una métrica única es peligrosa: separar criterios (precisión, tono, herramientas) reduce falsos positivos.
- Calibración no reemplaza seguridad: necesitas guardrails (controles de seguridad) con filtros, masking, políticas, además de calidad.
Impacto en Buk
Adoptar CC/CD para prompts nos permitió:
- Iterar más rápido sin “romper” producción.
- Pasar de discusiones subjetivas a decisiones con datos.
- Estandarizar el proceso de aprobación de prompts.
- Conectar evaluación Offline con monitoreo Online para cerrar el ciclo.
Conclusión
Evaluar prompts de forma consistente es uno de los desafíos más grandes cuando construyes aplicaciones con LLMs: el comportamiento no es determinista y un cambio pequeño puede mejorar algunos casos mientras degrada otros. En este post recorrimos una forma de enfrentar ese problema con un enfoque basado en evidencia: trabajar con datasets, diseñar evaluaciones, y apoyarnos en LLM-as-a-Judge para traducir criterios cualitativos (precisión, tono, uso de herramientas) a métricas que puedan compararse entre versiones.
Implementar el marco CC/CD (Continuous Calibration / Continuous Development) y evaluaciones con LLM-as-a-Judge no es solo una mejora técnica; representa un cambio fundamental en nuestra mentalidad de desarrollo. Hemos dejado de tratar a los prompts como textos mágicos que se ajustan “a ojo” para tratarlos como componentes de software que requieren rigor, métricas y trazabilidad.
Las evaluaciones Offline y Online cumplen roles complementarios. Offline te permite probar cambios en un set estable y representativo, comparar versiones con condiciones similares y detectar regresiones antes de que lleguen a usuarios. Online, en cambio, te devuelve la verdad de producción: qué pasa con datos reales, dónde aparecen patrones de error, y qué segmentos se degradan. Cuando ambas se usan en conjunto, el resultado es un ciclo de mejora más rápido y, al mismo tiempo, más seguro.
Si hay un aprendizaje clave, es que la calidad de un prompt no depende solo de una “buena redacción”: depende del sistema que lo rodea. Con CC/CD, evals offline/online y observabilidad, puedes iterar sin perder control, priorizar mejoras por impacto y mantener un estándar de calidad a medida que el producto crece.
El viaje de CI/CD a CC/CD es un paso necesario para cualquier equipo que quiera escalar sus funcionalidades de IA más allá de un MVP (producto mínimo viable). En Buk, este enfoque nos ha permitido domesticar la incertidumbre del modelo y ponerla al servicio del producto.